The Agent That Doesn’t Lose Its Place
Building a support agent that survives the restart
When a system is down, a token has expired, or the process just died mid-investigation - is the part you actually have to build.
Anyone can build the support-bot demo. Wire a capable model to a ticket, give it read access to a couple of APIs, and watch it diagnose a clean failure on stage. It looks like magic. It is also the easy 20%.
Then you put it in front of a real queue. Unattended. Overnight. Reaching into half a dozen live systems, any of which can be slow, broken, or mid-deploy at the exact moment the agent knocks. The demo agent doesn’t survive that. It stalls on the first timeout, loses its place on the first restart, and the next morning you find a row of half-finished investigations and no record of what they tried.
The hard part of an autonomous support agent isn’t the diagnosis. It’s persistence, the unglamorous discipline of not losing your place when the world around you misbehaves.
We borrowed the idea from the agentic coding tools we already live in, like Claude Code: a loop that keeps its footing. It remembers what it’s done, retries what failed, adapts when a step is refused, and picks up where it left off. None of that is the model. It’s the scaffolding around the model. So when we built our support agent, we treated that scaffolding as the product, not an afterthought. Here is what it actually takes.
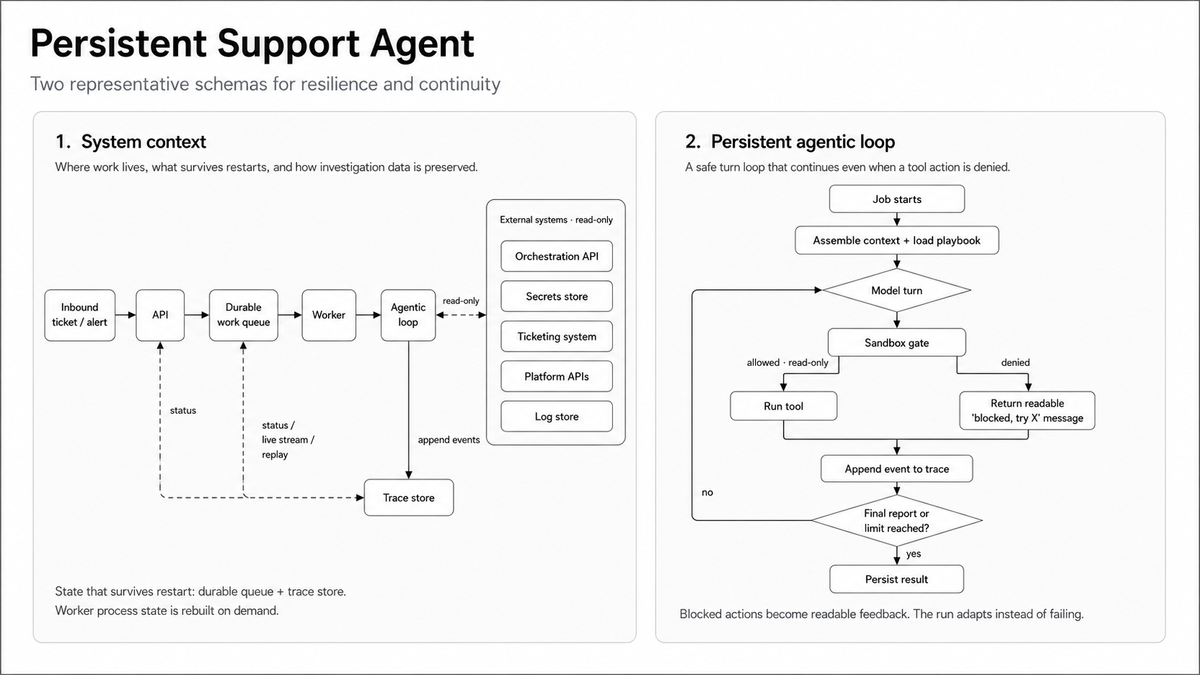
1. The work has to outlive the process
Every ticket becomes a durable job, not a request held in memory. It lands in a queue that lives outside the agent, so if the worker is killed mid-investigation (deploy, crash, OOM, a careless kill -9), the job is still there when the lights come back on.
And it comes back honestly. On restart, anything that was “running” when the process died gets caught and marked, not left hanging as a zombie that the dashboard quietly lies about. The state of every job is always queryable, always truthful. That’s the floor: the agent can die, the work cannot.
2. The agent has to remember what it did
Every step the agent takes (each model turn, each tool call, the command it ran, the result it got back, the action that was blocked, the assumption it had to make) is written to an append-only log as it happens, one line at a time. Think black-box recorder, not a summary written at the end (the end is exactly when you don’t get to write anything).
So any investigation can be replayed after the fact, in order, by anyone. This is the difference between “the agent failed, please investigate” and a complete transcript of what it tried, in what sequence, and where it hit the wall. One of those is a ticket nobody wants. The other is a colleague’s handoff notes.
3. Degrade, don’t die
The agent depends on systems it doesn’t own: a secrets store, an orchestration API, the ticketing system, the platform’s own APIs, the log store. In production, “all of them healthy at once” is the exception, not the rule.
So a dependency being down is a condition the agent handles, not an exception that kills it. If it can’t resolve a particular tenant’s credentials, it doesn’t abort; it proceeds with whatever it can reach, and it says so plainly in the record. If an access token expires mid-run, it refreshes and keeps going. The agent is built to do useful work with partial information, because partial information is the normal case.
4. A blocked action is a message
The agent is read-only by construction. Anything that could change state is blocked at the gate before it ever runs: no writes, no deletes, no destructive commands, no exceptions. You don’t trust an unattended agent not to do damage; you make damage impossible.
But here’s the part that matters for persistence: when the sandbox refuses a command, it doesn’t throw an error that unwinds the whole run. It hands the agent a readable reason (“that path is read-only; use the query endpoint instead”), and the loop continues, with the agent adjusting its approach. Same trick the good coding agents use. A denied tool is feedback, not a fatal error.
5. Exhaust the layers before you escalate
The agent investigates in layers, from the cheap broad signals down to the specific deep ones, trying alternatives and dropping to the next source when one comes up empty. It only escalates to a human after it has actually run out of things to check.
And when it does escalate, it doesn’t dump a shrug into the queue. It hands over the full context, what it confirmed, what it couldn’t reach, what it had to assume, and what it recommends next:
Investigation: Inconclusive, escalated to on-call.
Confirmed:
• Instance exists, in ERROR state, on a region reporting healthy capacity.
• Tenant quota not exhausted.
Could not reach:
• Per-tenant secrets (store timed out) → continued with reduced access.
Assumptions logged:
• Fault attributed to scheduler, inferred from the most recent platform signal.
Recommended next actions:
• Route to on-call with the trace below; confirm scheduler health for that region.
That is not a bot giving up. That is a co-worker who did the legwork, knew the limits of what it could see, and tapped the right person on the shoulder with everything they need.
The business case, said plainly
The reason this is worth the upfront work shows up in four places:
- Continuity. It survives the 3 a.m. restart. The queue doesn’t lose tickets and the agent doesn’t lose its place, so unattended actually means unattended.
- Trust. It tells you what it knew, what it didn’t, and why. People stop second-guessing it, which is the only way they ever start relying on it.
- Auditability. Every run is replayable, step by step. When someone asks “why did it say that” three weeks later, the answer is a file, not a guess.
- Throughput. Humans only see the tickets that genuinely need a human, each one arriving with the investigation already done.
The closing thought
The model is what makes the agent smart for a single step. Persistence is what makes it dependable across ten thousand of them. One of those you can buy off a leaderboard. The other you have to build, and it is mostly queues, logs, fallbacks, and the discipline to assume every dependency is having a bad day.
If your agent looks brilliant in the demo and brittle in production, the gap usually isn’t the model. It’s everything underneath that lets it keep going when something breaks, because in production, something always does.
That’s the part we build.
Want to talk about where your agent gets brittle between the demo and production? Get in touch at dvloper.io.
Razvan Georgescu, VP of Data & AI, dvloper.io