JiraAI: Turning a Decade of Jira Tickets Into an Answer Engine Your Team Can Actually Trust

The problem every growing engineering organization eventually runs into
At some point, every team stops being able to remember everything it has already learned. The knowledge is there sitting in ten thousand Jira tickets, buried in comment threads, resolution summaries, and carefully-written post-mortems of incidents from years ago. All of it is searchable, technically. None of it is findable in the way a human actually asks questions.
New team members spend their first weeks asking questions that have been answered a dozen times before. Senior engineers get pulled off their own work to explain history they’ve already explained, which isn’t just a productivity tax it’s one of the quieter reasons people burn out. Incidents drag on longer than they should because nobody can remember whether this exact symptom has happened before, or whether a similar issue in a different service was already root-caused and resolved.
The organization owns the answers. It just can’t access them at the speed of conversation. That gap between “we know this” and “we can retrieve this” is worth closing. That’s the problem JiraAI was built to solve at dvloper.io.
Why we built our own product layer
Before we wrote a line of code, we spent serious time evaluating RagFlow, the open-source RAG engine that has become one of the most capable platforms in its category. It’s genuinely impressive: deep document parsing, intelligent chunking, multi-modal retrieval, grounded citations, agent workflows, and native Jira support since v0.22.0. For many teams, it’s an excellent starting point. Three concerns ruled out a direct deployment for us.
Access control you can prove
Engineering managers and security leads don’t just want “a chatbot over Jira.” They want to prove that a contractor on Project A has no path through the UI, through the API, or by guessing identifiers to data from Project B. RagFlow’s open-source edition is designed around workspaces, not per-user per-knowledge-base grants. The maintainers confirmed this when they closed the RBAC request in May 2025: granular permission control is a commercial-tier feature. For our use case, this wasn’t a limitation we could work around it was the core of what we needed to deliver.
Roadmap autonomy
Building entirely on a third-party platform means your product’s future is tied to their release schedule and licensing decisions. Owning the application layer while leaning on RagFlow as the retrieval engine underneath meant we could ship the features our teams actually asked for, on our timeline, without waiting for an external roadmap to catch up.
Technology vs. product
A RAG engine does one thing extraordinarily well: retrieve. A knowledge product is the onboarding flow that makes a junior engineer feel supported, the audit trail that satisfies a security review, the dashboard that justifies the budget. None of that ships inside a retrieval engine by default. JiraAI is the product. RagFlow is the engine. Keeping those two things separate, and letting each do what it’s best at, is the most important architectural decision we’ve made on this project.
What JiraAI delivers
1. Real RBAC tied to your existing identity
JiraAI integrates directly with Keycloak (or any OIDC-compliant IdP). Access is enforced at three independent levels: site-wide roles (site.admin, project.admin, project.user), per-user knowledge base grants for contractors and cross-functional contributors, and project-to-knowledge-base mappings that make tenancy clean and auditable. One Keycloak change grants access; one change removes it entirely. MFA, session policies, and password rotation are all inherited JiraAI can’t accidentally weaken them. For a security review, this is the difference between a two-week conversation and a two-day one.
2. An admin dashboard for decision-makers
Every early demo ended with leadership asking the same three questions: Is anyone actually using this? Are the answers good? What are we getting for what we’re spending? The /admin view answers all three adoption by team and project trended over time, per-response helpfulness signals captured directly in chat, and LLM usage tied to specific tickets and projects. It’s a product owner’s view of whether the thing is working, not a RAG operator’s view of embedding health and vector metrics.
3. Jira data understood before it’s indexed
Raw Jira tickets are noisy: triage summaries written before the problem was understood, low-signal comments (“bump,” “retry,” “any update?”), attachments in mixed formats, and resolutions buried in the last reply of a long thread. Feed that directly into a knowledge base and you get answers that reflect the noise.
JiraAI’s ingestion pipeline runs every ticket through an AI enrichment step before it reaches the knowledge base restructuring it into what the problem was, what was tried, what was ruled out, and what finally worked. Atlassian Document Format comments are parsed correctly. A single ticket can fan out to multiple knowledge bases without duplicating the enrichment work. The result is cleaner retrieval and more accurate, more specific answers.
4. Project-centric UX and a resilient pipeline
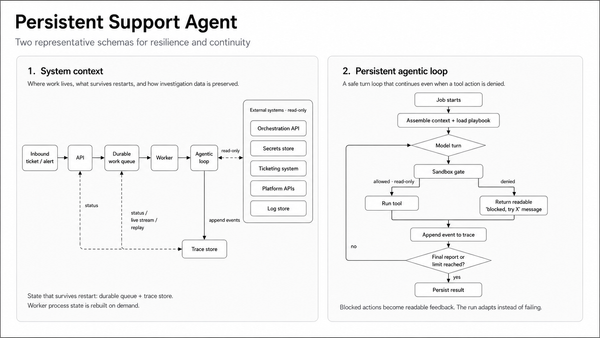
Instead of navigating a list of opaque knowledge base identifiers, users start from a project, intuitive and familiar organizing unit they already work in every day. The assistant, access controls, and analytics all follow automatically. Behind the scenes, a decoupled producer/consumer pipeline handles incremental Jira polling, enrichment, and fan-out independently. If the downstream is temporarily unavailable, the producer keeps collecting and the consumer catches up. Single-ticket failures don’t affect the batch. Idempotency is enforced at the database level. Reliability isn’t a feature you market it’s the absence of the outages you didn’t have.
How a question becomes an answer
An engineer hits a familiar-looking Kafka consumer timeout and types: “Have we seen this lag spike before, and what was the fix?” JiraAI authenticates them via Keycloak, resolves their project memberships, and queries only the knowledge bases they’re allowed to see the access boundary is enforced at the retrieval step, not just at the UI. Enriched ticket chunks are retrieved, re-ranked, and passed to the LLM with a carefully designed system prompt. The answer streams back with citations to specific tickets.
The engineer clicks through to an eleven-month-old ticket and finds the root cause in three minutes. They mark the response helpful that signal feeds the admin dashboard, where a product owner can see which teams are getting value and which knowledge bases have gaps. Nobody thought about knowledge base IDs, RAG configuration, or which model is powering the response. It just worked, and it was safe, and it was measurable.
The lesson
Retrieval engines don’t ship with the parts that make them products. Access control, audit trails, domain-specific data handling, a UX that fits how engineers think about their work none of that comes in the box, regardless of how good the underlying engine is. A thin interface on top of RagFlow would have passed the demo. It would not have passed the security review.
So we built those parts ourselves and layered them on top of RagFlow’s retrieval quality, which we trust and don’t have to maintain. The hard foundational work is someone else’s problem. The product experience the part our teams open every morning is entirely ours to shape and iterate on.
Further reading
– RAGFlow v0.22.0 data sources, admin UI, parser improvements